Project Details:
This is a broad description of a project you might be working on! More projects upcoming!
Computer Vision under the Assumption of Value
Abstract:
Real world computer vision systems typically have some intrinsic value in their underlying business use. Serving the the right image in a search result ad might be worth $0.001 and counting nuclear particles in material images might be worth $10,000. In general we want to build systems which produce sufficiently accurate results within the budget. Although human interaction can improve accuracy in many algorithms, it also costs money. Most computer vision research has focused on purely automated algorithms, arguing that human labor is much too expensive to include in operational algorithms. This is equivalent to finding solutions for the $0.00 value case. We should explicitly investigate joint algorithms using computers and human labor, and report accuracy as a Cost vs Accuracy curve as additional human labor is inserted. We investigate some representative computer vision tasks, e.g. Object Detection, Image Matching, and X. We introduce several general strategies for combining existing vision algorithms with human labor, e.g. PruneFalsePositives, Y, Z. These strategies provide for increased accuracy in those cases when the task has positive value.
Keywords: computer vision, human computation, crowdsourcing, human-computer interaction
Wait, I didn't understand that at all. Can you please help me explain?
Sure! but first let's try to understand two terms here: Computer Vision and Crowdsourcing.
Computer Vision is a field of computer science that includes methods for acquiring, processing, analyzing, and understanding images. It helps computers to conduct tasks like detecting events, object recognition, navitating robots, controlling processes and more. It gives eyes to a computer.
Crowdsourcing is an approach to harness the expertise or intelligence of a distributed group of people, to solve a problem or execute any given task. Some common examples of crowdsourcing projects are Wikipedia, OpenStreetMaps and Captcha - in all of these projects, distributed group of people patricipated for a cause and helped write an encyclopedia, map geographical places and digitized books, respectively. To harness crowd potential, some have also turned to crowdsourcing marketplaces like Amazon Mechanical Turk and Crowdflower to execute microtasks like labeling images or transcribing audio from thousands of people for a small amount of money.
That's cool! but why do I need to know about these terms and how are they related?
Now, computer vision is NOT perfect, in fact its far from being perfect, specially when it comes to recognizing a variety of objects in different type of images. Meanwhile, we humans are blessed with a brain which can process complex images, and recognize objects within them. This leads to a logical question, which is that why can't we use humans to recognize objects instead of computers? What's the catch?
The catch is that human services are not free, and may encounter speed and scalability issues. A typical object annotation task on Mechanical Turk can cost from few cents to few dollars depending on the type of images and accuracy requirements. Computer vision on the other hand is practically free and scalable, however, lacks accuracy (please see the image below). This raises few questions!
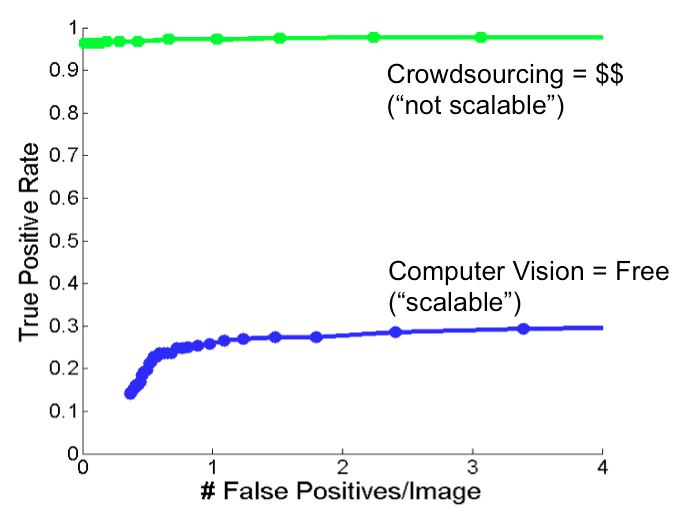 -Can we use advance computer vision algorithms with crowdsourcing techniques to improve the accuracy while keeping the cost low?
-Can we use advance computer vision algorithms with crowdsourcing techniques to improve the accuracy while keeping the cost low?
-Can we design an algorithm combining the both? What would be the trade off? and how would the graph look like?
-Can we building something like Soylent? for computer vision tasks like object recognition...
This project explores these research questions, and requires you to generate graphs which shows the relationship of cost vs. accuracy on applying state-of-the-art computer vision algorithms with best crowdsourcing techniques.
What graphs? I am still a bit confused...
Okay, let me clarify a bit more. See the image below. It shows two scenarios - 1) when using crowdsourcing, we can achieve highest level of accuracy, but its expensive. 2) even the state-of-the-art computer vision algorithm falls short of great accuracy, but it practically costs nothing.

Now imagine the graph shown below. Can we generate a graph like this? Showing the performance of an algorithm combining computer vision and crowdsourcing techniques? Trying to maximize the accuracy while minimizing cost? -- Well, that's the kind of graph we're looking for.
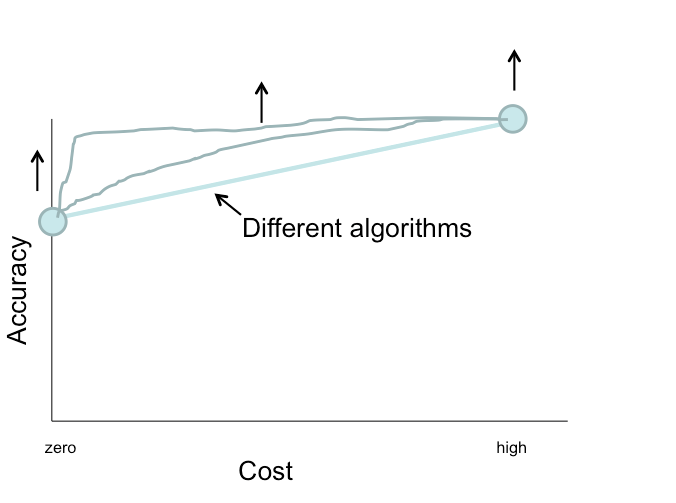
In this project, we want you to try a variety of algorithms and approaches combining computer vision and crowdsourcing techniques to generate graphs showing the results. Some of the tasks and their strategies are shown below for reference:

I hope you understand the project on a higher level by now. If not, don't worry. We'll have weekly meetings and will set up a private Google Group for you guys to interact and post questions.
How is this project impactful?
Since the inception of computer vision, scientists have strived to achieve 100% accuracy on tasks like object detection. However, even after 40 years of research, we're not there yet. Meanwhile, recent surge in human computation or crowdsourcing techniques/platforms have given us an opportunity, a tool to harness brain power on scale. We believe that from the results generated, future applications or systems can be built to achieve higher level of accuracy with minimal cost. It can foster healthcare by helping scientists detect cancer cells, or identifying criminals from long footage of videos, the applications and impact are abundant!
What help do I get?
As a participant and co-researcher, you'll get access to all necessary resources. This would include the right dataset, and funding to run experiments on Amazon Mechanical Turk or other platforms. Above all, your team gets to participate in a weekly meeting with the professor to help you with the project.
Helpful Papers
CrowdFlow: Integrating Machine Learning with
Mechanical Turk for Speed-Cost-Quality Flexibility. Alex Quinn, et. al. U. Maryland TR 2010. [pdf]
Crowdsourcing Annotations for Visual Object Detection.
Hao Su, et. al. AAAI HCOMP 2012. [pdf]
The HPU.
James Davis, et. al. IEEE CVPR 2010. [pdf]
Soylent: A Word Processor with a Crowd Inside.
Michael S. Bernstein, et. al. ACM UIST 2010. [pdf]
Distributed Human Computation.
Serge Belongie, et. al. [link]


